
Calculateur CEMAG//Base d'archives CEMAG
Dernière mise à jour 03-09-2009 10:41 / Jean-François RabasseRetour rubrique Calculateur CEMAG
(Ce texte n'est pas disponible en français, nous nous en excusons.)
The CEMAG archives Database
The CEMAG archives Database (http://cemag.ens.fr/) is a tree of data holders objects. These objects group and structure the effective data files storage, providing a logical scientifical frame and featuring navigation across the database.
Contents
The main objects structure
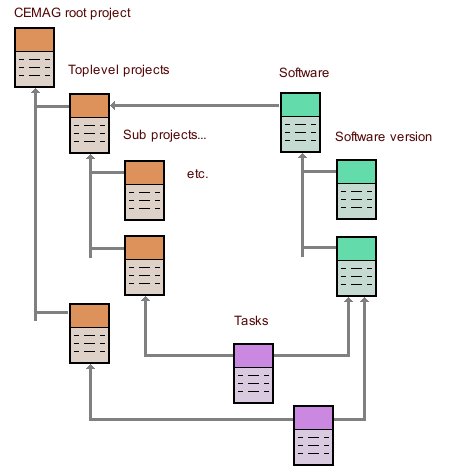
Projects
Projects are the fundamental structure entities. They are created attached to another project, in any number, and can be subdivided into sub-projects at any nesting depth. (The structure is the same as a disk filesystem directories and sub-directories tree.)
So called toplevel projects are those directly attached to the root CEMAG project.
Software tools
These objects are created to reference, document, archive, software programs run by the CEMAG users. The structure is a two levels tree. Software objects relate to generic programs, e.g. Ramses, ZEUS, Parody, IDL, etc. and software versions objects relate to one binary instance of a program, e.g. ZEUS 3D 1.6, Ramses MHD 2.0, etc.
Software objects can be attached to any project object of the Database. Widely used programs should probably be attached directly to the CEMAG project, while user specific programs will be connected to one of the user's projects.
Tasks
Tasks are special objects with two reference links; tasks belong to a project or subproject and tasks reference a software version.
Typical use is to hold numerical simulations data files, keeping track of the scientifical context, «For which project was that job run ?», and the technical frame, «With which program and version was it done ?»
Associated data
 All users data files will be stored and registered as associations to
any structure object, a project, a software, a task.
All users data files will be stored and registered as associations to
any structure object, a project, a software, a task.
Database objects accept any number of associated data, hold the framework links and the description of the data set. Associated data can be any kind of file, computations results (for tasks objects), tar-gzipped source code (for software objects), scientifical articles (for project objects) etc.
Current version of the Database software implements also external
web links that can be useful to add documentation via a pointer to
a web page (e.g. Homepage of a software, etc.)
Other specific data types (images, videos, ...) may be implemented in the future.
An example object :
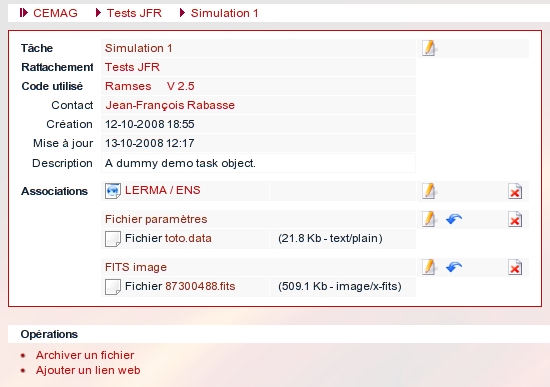
The above partial screenshot displays a (dummy) database object. It's a task object, named Simulation 1, attached to sub-project Tests JFR, using version V 2.5 of the Ramses program.
This objects holds three associated data, a pointer to the LERMA / ENS web site and two files, a small text file and a FITS image.
Each component, the task object itself and its associates, provides handling commands via icons links (on the right) to edit the object data, extract files from archives, delete the data.
The interface provides also, at the bottom, a list of available operations on the current object. Here, one can associate a new file or a new web link.
Navigation through the base
Database objects display page provides all pertinent links to other objects. At the top, a navigation line shows the position of the current object in the projects tree, from top to bottom. It's possible to click and go to any ancestor.
The object itself display all its references, parent project, software used and version, object owner (creator), as links.
Last, the web interface main menu provides list oriented access. List of projects, list of sofware tools, list of users, and a per user list of favourites, i.e. the objects a user has been working on recently. This gives to users a straight access to their current work or simulation upon Database connection.
A search by keywords input field is also provided on the main interface. Keywords indexing is done, per object, with the owner name, object title, object description.
Using the Database
Public access will be possible (to be discussed), in consultation only mode. Database objects creation and data files archiving require a login account, for access control reasons and also for data ownership.
Potential users will contact me to have an account and also to ask for several (one, two, more ?) toplevel projects. Yes, creating objects, sub-projects, tasks, etc. requires to be owner of the parent project. Toplevel projects have the CEMAG root project as parent and as I am the owner of this root project, I need to create users toplevel projects.
After that step, any user will structure her/his data space with creation of sub-projects.
Probably (this can be discussed) toplevel projects should reflect independent scientifical studies domains. All information that relates to a same thematic should probably be organised as subdividisons.
Sub-projects
Each user is free to structure personal project space in a consistent way. The project tree is nothing but a helper tool to organise data.
Please, dont' forget to give your projects title and description, the keywords search needs that. A short description, two or three lines with pertinent key-words will do.
Software
Before creating tasks objects, some software and software versions must be available. Register the software you use and which versions.
Software objects can be attached to any project object, even if not owned by the current logged in user. Multi users software should probably be attached to CEMAG.
When possible, save source code with software versions. Tar-zip your source directories and associate the tar file. This will be very helpful in a future (maybe years later), should someone wish to replay a run with exactly the same program.
Tasks and files
Create tasks to group results. A typical simulation task will hold run configuration files, submission scripts, raw output files, post processed files, videos files, etc.
The task is a logical entity, not necesseraly one run. A task may be several runs (with the same program version) done to study such or such influence. It will be useful to have all that grouped.
Moving data files
The Database users interface does not perform any data transfer. (It runs on the lab web server and doesn't know anything about the JxB computer, storage servers and others).
Files archival and archives extraction operations, as featured from the interface, are nothing but requests. Separate data transfer servers will run on the CEMAG machines network (jxb, imag, others) and will move, one way or the other, data files then update the database.
Thus, these operations are not immediate. Transfer services will synchronise at regular time intervals, once an hour, once a day, we'll see what is the best. Anyway, this is an archival service, not a runtime files copy command.
NB: after successfull archival, the original file is removed from its source location. (Archival intends also to free disk workspace...)
Files transfer command line tool
The Web interface is a convenient tool to handle the structure, projects, software, tasks, and reflects the «tree view».
To archive files, simulations results et al., this interface is probably not very handsome and may even be boring for users having great quantities of files.
A command line program, named acemove (for Archives CEMAG move), is available on the jxb computer and the imag workstation. The syntax can be reminded via option -help
rabasse@jxb00:~> acemove -help CEMAG DB V 1.4.2 archival/recovery utility program Generated on 2009-04-27 18:34 for ia64 Linux 2.6.16.46-0.12-default Usage: acemove -s sim-name files-to-archive ... Save files to simulation/task (must be owner or admin). Files-to-archive is a list of files names (or meta, e.g. *.data) with optional embedded titles and/or notes. E.g. -t "Title1" -n "Note1"-t "Title2" etc. Usage: acemove -r sim-name [files-to-recover ...] Recover all files from simulation/task if no files list, or recover selected files, by title, name or DB ident. Recovery is done into the current directory (must have write access).
Saving files
A simulation or task must have been created in the Database and must belong to the current user. The name can be specified in abbreviated form, case insensitive, but must be unambiguous.
Should the specified name be too short and ambiguous, an error message is issued, e.g. :
rabasse@jxb00:~> acemove -s simul -t "Resultats Run 3" data3.out
Task name "simul" could reference 2 objects :
146 : "Simulation 2"
120 : "Simulation test"
Please, use a non ambiguous name or DB ident
In that case, one will repeat the command with the full name, or at least enough characters, e.g. :
rabasse@jxb00:~> acemove -s "simulation te" ...
or using the target object Database numeric ident (as displayed in the error message) :
rabasse@jxb00:~> acemove -s 120 ...
NB: when a name contains spaces, Unix command line syntax requires it be quoted !
The list of files to archive may be selected files names, in the current directory, or may use meta characters, e.g. :
rabasse@jxb00:~> acemove -s "simulation te" *.out
(This latter form is convenient to archive in one command all of the content of a directory.)
The list may also contain directories names. In that case, the whole directories trees will be archived, all files and possible subdirectories. This may be convenient for some numerical programs that output a structured subdirectories tree per run, with tens of files. A single save command, with the name of the run top directory will do.
The Web interface provides input fields to set a title and comments notes with archived files. The acemove program provides options to do this by embedding titles and notes among the files list.
IMPORTANT: files are NOT moved at once. The program schedules archival requests that will be processed by the Database updater, usualy in the next few hours. Thus, they should not be removed once the command is issued.
Archived files are removed, and disk space freed, upon successful archival. A report is send to the user by e-mail, as in the case of archivals via the Web interface.
IMPORTANT: files to archive will usualy be in the disks workspaces of the machines, directories /jxb-data/01 to /jxb-data/06 on the Altix computer, /scratch on the imag workstation.
Don't try to archives files on home directories, on the imag machine. These directories are not local disks but network mounted filesystems and the acemove program won't handle that.
Also, be clever : the imag workstation «sees» the jxb data disks, via a network mount. But this is not magic at all and consumes network bandwidth. Don't issue acemove commands from the imag station to archive files seen on the /jxb-data disks. This will work, indeed, but data will move via the network from jxb to imag, then from imag to the storage server. It will be far more efficient to log in jxb to issue the archival commands.
Recovering files
The reverse function, recovering files from a simulation or task, is performed in a similar way :
rabasse@jxb00:~> acemove -r "Simulation test" data1.out data3.out
The command must be run from the desired destination directory. (Directory must belong to the current user.)
The name of the simulation must be unambiguous, same as for the archival command. Files to recover can be specified by their title or file name. Ambiguous names will produce an error message with the list of names and numeric idents, same as for simulations.
IMPORTANT: files recovery is done at once, not by scheduling recovery requests. Recovering is not archival and, in most cases, people will want their file(s) as soon as possible. So, transfer is executed when the command is executed. It may take some time, depending on the total data size. A good evaluation basis is 20 to 40 Mbytes per second. Don't try to recover hundreds of Gigabytes in one command, or you may have to wait a couple of hours.